2024年9月23日
- 部署了新版本 RSK-P121p5 (
v3/pdf*) - 转换改进
2024年9月23日
- 部署了新版本: RSK-M132p12 (
v3/text) 和 RSK-P121p4 (v3/pdf*) - 后处理改进
2024年9月20日
- 部署了新版本: RSK-M132p11i1 (
v3/text) 和 RSK-P121i1p3 (v3/pdf*) - 更频繁地选择表格分割作为表格OCR算法
2024年9月18日
- 部署了新版本 RSK-M132p10i1 (
v3/text) 和 RSK-P121i1p2 (v3/pdf) - 修复了某些情况下
latex_styled格式的重复输出 - 后处理变更 (
v3/pdf)
2024年9月12日
- 部署了新版本 RSK-P121i1p1 (
v3/pdf) - 修复了极少数情况下图表后处理错误的问题
2024年9月10日
- 部署了新版本 RSK-P121 (
v3/pdf) - 模型更新
2024年9月6日
- 部署了新版本 RSK-M132p9 (
v3/text) - 防止在某些情况下在输出中生成图表的图片链接
2024年9月5日
- 部署了新版本 RSK-P120 (
v3/pdf) - 模型更新
2024年9月2日
- 部署了新版本: RSK-M132p8 (
v3/text) 和 RSK-P119p1 (v3/pdf*) - 修正了在某些情况下发生的输出公式顺序错误问题
2024年9月1日
- 部署了新版本 RSK-P119 (
v3/pdf) - 模型重新训练,使用了更多数据
2024年8月30日
- 部署了新版本: RSK-M132p7 (
v3/text) 和 RSK-P118p10 (v3/pdf*) - 更新了 MathJax@3.2.2
- 改进了 Asciimath 输出,不再在函数名和括号之间额外添加空格 (例如
arctan((1)/(x))代替arctan ((1)/(x)))
2024年8月29日
- 部署了新版本: RSK-M132p6 (
v3/text) 和 RSK-P118p9 (v3/pdf) - 后处理修复。
2024年8月26日
- 将 OCR API 重命名为 Convert API
2024年8月23日
- 部署了新版本 RSK-P118p8 (
v3/pdf) - 代码块在多个页面连接时现在有双换行分隔,这更加一致(以前是单换行)。
- 部署了新版本:RSK-M132p5 (
v3/text) 和 RSK-P118p7 (v3/pdf) - 处理图表时改善了与文本行显著交叉的情况的后处理。
2024年8月21日
- 部署了新版本:RSK-M132p4 (
v3/text) 和 RSK-P118p6 (v3/pdf) - 修复了与代码识别和脚注文本相关的后处理问题。
- 修复了一些内部错误。
单行脚注文本有时会留未闭合,没有匹配的结束符。例如,API 返回的响应可能如下所示:
\footnotetext{
* My single line footnote
This deployment corrects it to:
\footnotetext{
* My single line footnote
}
在一些模糊情况下,我们遗漏了结束的三重反引号,这是 MMD 代码分隔符。这导致了这些情况下的渲染不正确。大多数这些情况,甚至所有这些情况,都应该通过此部署得到修复。
2024年8月20日
- 部署了新版本:RSK-M132p3 (
v3/text) 和 RSK-P118p5 (v3/pdf) - 改进了具有复杂单元内容的表格的处理。
此部署改进了表格 OCR,当表格的单元格包含复杂内容时。以下是一个具有复杂单元的非常简单表格的示例,仅用于说明这些更改的积极影响:

第二行的第一个单元格有 3 行文本和一个方程。表格处理成 MMD 如下:
\begin{tabular}{|c|c|c|}
\hline First column & Second column & Third column \\
\hline \begin{tabular}{l}
This cell has multiple lines \\
which enables testing tableocr properly. \\
Here goes the equation: \\
\( L=-\frac{1}{N} \sum_{i=0}^{N-1} y_{i} \log \left(\hat{y}_{i}\right) \)
\end{tabular} & Normal cell & Normal cell \\
\hline
\end{tabular}
渲染结果为:

2024年8月16日
- 部署了新版本:RSK-M132p2 (
v3/text) - 添加了缺失的行数据格式 (
data和html) - 解决了
v3/latex端点的一些错误报告不正确的问题
2024年8月15日
- 部署了新版本:RSK-M132p1 (
v3/text) 和 RSK-P118p4 (v3/pdf) - 为
v3/text启用了"include_equation_tags": boolean选项(默认为 false)。 - 后处理改进。
2024年8月14日
- 部署了新版本:RSK-P118p3 (
v3/pdf) - 修复了图表后处理问题。
- 添加了请求选项
include_smiles用于数字化化学图表(默认为 true)。当设置为 false 时,化学图表将以图像形式保留。
2024年8月10日
- 部署了新版本:RSK-P118p2 (
v3/pdf) - 修复了与方程处理相关的少见后处理问题。
2024年8月6日
- 部署了新版本:RSK-P118p1 (
v3/pdf) - 修复了与表格处理相关的后处理问题。
2024年7月29日
- 部署了新版本:RSK-M132 (
v3/text) 和 RSK-P118 (v3/pdf) - OCR 引擎更新
2024年7月26日
- 部署了新版本:RSK-P117p5i4 (
v3/pdf) - 在某些边缘情况下正确包括方程标签。
2024年7月10日
- 部署了新版本:RSK-M131p6i3 (
v3/text) 和 RSK-P117p3i2 (v3/pdf) - 我们现在将 “
” 移动到 “ ”。我们还提供了一个 API 选项 math_fonts_default_to_math用于禁用此行为。
2024年6月22日
- 部署了新版本 RSK-M131p6i2 (
v3/text) - 修复了在
"formats"请求参数中指定无效format时的内部错误。现在我们返回所有支持的格式的结果,并忽略不支持的格式。有关支持格式的详细信息,请参见 此处。
2024年6月19日
- 部署了新版本 RSK-M131p4i1 (
v3/text) - 修复了在正确检测到自动旋转的情况下错误旋转图像中的化学物质的解析问题。
2024年6月12日
- 部署了新版本 RSK-M131p3i1 (
v3/text) - 修复了检测图中错误项目的问题,即
contains_chart和contains_graph
2024年6月9日
- 部署了新版本 RSK-P117p1 (
v3/pdf) - 修复了后处理中的未识别表格处理问题。
2024年6月7日
- 部署了新版本 RSK-P117 (
v3/pdf) - 此更新修复了旋转侧边文本检测引起的问题,改善了源代码识别和对非常小的线(例如单字符线
{)的识别。
2024年5月31日
- 部署了新版本 RSK-P116p2i1 (
v3/pdf) - 给定
$作为内联数学分隔符,表单字段被识别为$\qquad$而不是$ \qquad $,因为前者在渲染时存在问题。
2024年5月30日
- 部署了新版本:RSK-M131p2i1 (
v3/text) 和 RSK-P116p1i1 (v3/pdf) - 后处理修复,消除了几个非常罕见的内部错误。我们现在要么返回请求的内容,要么在图像中没有内容时不返回任何内容。
2024年5月27日
- 部署了新版本:RSK-M131 (
v3/text) 和 RSK-P116 (v3/pdf) - 源代码识别的改进;对源代码中的非英语语言的支持
例如,给定如下图像:

返回的响应现在包括正确识别的中文汉字:
```
def test_function():
# 测试数字之和
sum: int = 0
for i in range(1, 11):
sum += i
assert sum == 55
```
2024年5月20日
- 部署了新版本:RSK-M130 (
v3/text) - 改进了子类型图表检测(新增
analytical子类型)
请求中指定了
"include_line_data": true 并且包含如下图像:
将会收到如下线数据:
[
{
"type": "text",
"cnt": [
[
29,
29
],
[
29,
0
],
[
368,
0
],
[
368,
29
]
],
"included": true,
"is_printed": true,
"is_handwritten": false,
"text": "What is the area of the trapezoid?",
"after_hyphen": false,
"confidence": 1.0,
"confidence_rate": 1.0
},
{
"type": "chart",
"cnt": [
[
303,
331
],
[
303,
62
],
[
681,
62
],
[
681,
331
]
],
"included": false,
"is_printed": true,
"is_handwritten": false,
"subtype": "analytical",
"error_id": "image_not_supported"
}
]
其中包含“类型”:“chart”和“子类型”:“analytical”的项目。
2024年5月15日
- 部署了新版本:RSK-P115 (
v3/pdf) - 改进了处理段落开头的大写字母(见下文)
对于像这样的情况,段落以非常大的字母开头:

我们现在返回正确识别的文本为:
现在有大量的文献将宗教与...其他文本联系起来...
重点是启动T的正确处理。
2024年5月9日
- 部署了新版本:RSK-M129p2i1 (
v3/text) 和 RSK-P114p2i1 (v3/pdf) - 性能改进:
- 所有端点的响应时间更快。
- 大型PDF文件的状态从
loaded到split的转换速度更快(分割时间)。
2024年5月1日
- 部署了新版本:RSK-M129p1 (
v3/text) 和 RSK-P114p1 (v3/pdf) - 源代码后处理更新:
- 将
\rightarrow转换为-> - 将
\Rightarrow转换为=>
- 将
2024年4月30日
- 部署了新版本:RSK-M129 (
v3/text) 和 RSK-P114 (v3/pdf) - 更新改进了手写日文和源代码识别
此更新初步支持从图像中正确识别源代码。例如,对于如下源代码列表的图像:

Mathpix 现在返回:
object TypeChecker {
public:
void Visit(AssignmentNode & n) {
// …
Visit (n.LHS ());
Visit (n.RHS ());
// …
}
void Visit(VariableRefNode & n);
// …
};
object CodeGenerator {
public:
void Visit(AssignmentNode & n);
void Visit(VariableRefNode & n);
// …
};
Node & root = // …
TypeChecker.Visit(root);
CodeGenerator.Visit(root);
public:
void Visit(AssignmentNode & n) {
// …
Visit (n.LHS ());
Visit (n.RHS ());
// …
}
void Visit(VariableRefNode & n);
// …
};
object CodeGenerator {
public:
void Visit(AssignmentNode & n);
void Visit(VariableRefNode & n);
// …
};
Node & root = // …
TypeChecker.Visit(root);
CodeGenerator.Visit(root);
2024年4月30日(续)
- 更新后渲染效果如下:

同样,伪代码也被包裹在三个反引号中,而带有数学符号的LaTeX格式则被输出。请注意,这种伪代码格式未来可能会发生变化。
对于如下伪代码图像:

返回的输出如下所示:
```
算法 3 在子表达式中分配给定大小预算的算法 ${ }^{9}$
func Divide ( $a$ : Arity, $q$ : Size, $l$ : Op. Level, $j$ : Expr. Level, $\alpha$ : Accumulated Args.)
- Requires: $1 \leq a \leq q \wedge l \leq j$
if $a=1$ then
if $l=j \vee \exists\langle x, y\rangle \in \alpha: x=j$ then return $\{(1, q) \diamond \alpha, \ldots,(j, q) \diamond \alpha\}$
return $\{(j, q) \diamond \alpha\}$
$L=\{\}$
for $u \leftarrow 1$ to $j$ do
for $v \leftarrow 1$ to $(q-a+1)$ do
$L \leftarrow L \cup \operatorname{DIVIDE}(a-1, q-v, l, j,(u, v) \diamond \alpha)$
return $L$
```
2024年4月27日
- 部署了新版本:RSK-M128p3 (
v3/text) 和 RSK-P113i1p1 (v3/pdf)- 现在将
\begin{array}{l}{...x...}\\{...y...}\end{array}转换为\binom{...x...}{...y...}。
- 现在将
2024年4月18日
- 部署了新版本:RSK-M128p2 (
v3/text)- 小的后处理修复。
- 部署了新版本:RSK-P112 (
v3/pdf*)- 初步支持检测待填充的文本占位符 (
form_field)。 - 更新了算法以增加更多数据。
- 初步支持检测待填充的文本占位符 (
2024年4月4日
- 部署了新版本:RSK-M128 (
v3/text)- 改进了源代码和伪代码的缩进。
- 源代码用三重反引号括起来。
- 支持检测待填充的文本占位符 (
form_field):- 占位符下划线、点和破折号输出为
\( \\qquad \)。 - 占位符框输出为
\(\square\)。
- 占位符下划线、点和破折号输出为
- 改进了源代码和伪代码的缩进。
2024年3月26日
- 部署了新版本:RSK-P111p6i2 (
v3/pdf*)- 改进了DOCX导出:添加了对嵌套文本表格的扁平化处理,如果嵌套表格只有一列且有多行。
2024年3月15日
- 部署了新版本:RSK-P111p5i2 (
v3/pdf*)MMD到PDF-LaTeX转换改进:- 添加了额外的字体,以支持更广泛的脚本。
- 扩展了语言检测功能,以准确且更可靠地处理文本。
- 语言检测扩展到包括泰语、泰米尔语、希伯来语、印地语和孟加拉语。
- 对于包含非拉丁、希腊、斯拉夫(LGC)脚本的文档,自动使用XeLaTeX,以确保更好的多语言文本渲染。
- 对于非LGC脚本的文档,统一使用Noto系列字体,提供一致性和广泛的脚本支持。
MMD到LaTeX转换和tex.zip扩展的输出现在可能包含需要XeLaTeX才能正确渲染的代码。值得注意的是,只有Note到PDF-LaTeX允许特定字体选择。对于MMD到LaTeX和tex.zip扩展的输出,转换统一为CMU Serif和Noto Serif用于非LGC脚本。
2024年3月13日
- 部署了新版本:RSK-M127p5i1 (
v3/text)- 修正了Asciimath输出中“插入符号”的重复错误(例如,将
100(1.03)^2t=5000更正为100(1.03)^(^^)2t=5000)。
- 修正了Asciimath输出中“插入符号”的重复错误(例如,将
- 部署了新版本:RSK-P111p4i2 (
v3/pdf*)- 改进了DOCX导出:添加了自动检测整个文档语言的功能。
2024年2月29日
- 部署了新版本:RSK-M127p4i1 (
v3/text和v3/latex) 和 RSK-P111p3i2 (v3/pdf*) - 一般效率改进。
2024年2月26日
- 部署了新版本:RSK-P111p3i1 (
v3/pdf*) - 改进了LaTeX导出(tex.zip):现在我们在目录和各个部分中使用双反斜杠(
\\)进行换行,而不会在文本模式下开始新段落。
2024年2月22日
- 部署了新版本:RSK-M127p3 (
v3/text) - 修复了Asciimath输出中分数函数参数的错误分组,分数函数参数现在通过括号正确包含在函数中(例如,将
sec ((5theta)/(4))=2更正为sec (5theta)/(4)=2,以及log ((x)/(y^(5)))更正为log (x)/(y^(5)))。
2024年2月16日
- 部署了新版本:RSK-M127p3 (
v3/text和v3/latex) - 现在我们验证
region参数,并返回适当的错误信息。
2024年2月6日
- 部署了新版本:RSK-P111p2 (
v3/pdf*) - 新增了API选项
"include_equation_tags": boolean
我们很高兴宣布对
v3/pdf* 端点的增强:现在可以在MMD输出中直接包含识别的方程编号。之前,方程编号只能通过 lines.json 输出格式访问,主要用于搜索目的,而在主MMD内容中不可见。通过新的
"include_equation_tags": true 参数,我们的系统现在将方程编号无缝地集成到MMD输出中,使用 \tag 元素进行清晰的关联。此改进通过直接将方程与其相应编号链接,丰富了MMD文件,便于引用和导航。以下是结果变化的示例:
对于PDF文件的这一部分

我们当前返回的MMD如下:
从麦克斯韦方程中很难立即看出时变电流是辐射源。麦克斯韦方程的简单变换
\[
\begin{aligned}
\nabla \times \mathbf{E} & =-\mu \frac{\partial \mathbf{H}}{\partial t} \\
\nabla \times \mathbf{H} & =\varepsilon \frac{\partial \mathbf{E}}{\partial t}+\mathbf{J}
\end{aligned}
\]
化为 \(\mathbf{E}\) 或 \(\mathbf{H}\) 的一个二阶方程证明了这一说法。通过取 (1.2) 中第一个方程两边的旋度并利用 (1.2) 中的第二个方程,我们得到
\[
\nabla \times \nabla \times \mathbf{E}+\mu \varepsilon \frac{\partial^{2} \mathbf{E}}{\partial t^{2}}=-\mu \frac{\partial \mathbf{J}}{\partial t}
\]
从 (1.3) 可知,电流对时间的导数是波状矢量 \(\mathbf{E}\) 的来源。
启用新选项(“include_equation_tags”:true)后,我们现在返回:
从麦克斯韦方程中很难立即看出时变电流是辐射源。麦克斯韦方程的简单变换
\[
\begin{align*}
\nabla \times \mathbf{E} & =-\mu \frac{\partial \mathbf{H}}{\partial t} \tag{1.2a}\\
\nabla \times \mathbf{H} & =\varepsilon \frac{\partial \mathbf{E}}{\partial t}+\mathbf{J} \tag{1.2b}
\end{align*}
\]
将这两个方程合并成一个关于 \(\mathbf{E}\) 或 \(\mathbf{H}\) 的二阶方程可以证明这一声明。通过对(1.2)中的第一个方程的两边取旋度,并利用(1.2)中的第二个方程,我们得到:
\[
\begin{equation*}
\nabla \times \nabla \times \mathbf{E}+\mu \varepsilon \frac{\partial^{2} \mathbf{E}}{\partial t^{2}}=-\mu \frac{\partial \mathbf{J}}{\partial t} \tag{1.3}
\end{equation*}
\]
从 (1.3) 可知,电流对时间的导数是波状矢量 \(\mathbf{E}\) 的来源。
除了添加的方程编号,输出中还有其他差异:
- 单个编号的方程现在用
\begin{equation*}...\end{equation*}包裹以支持编号。 aligned环境现在被替换为align*以支持编号。- 我们也将
gathered替换为gather*。 - 总的来说,当使用
"include_equation_tags": true时,我们将使用支持编号的环境。
- 我们也将
- 这些变化在
lines.mmd.json格式中也能看到。
以下是识别的 PDF 页面部分的渲染效果:

请注意当前实现中的一些限制:
- 我们不会生成文本中的方程引用(例如
\ref{eq:1.3})。在给定示例中,最后一段引用了方程(1.3)。虽然这个引用很直接,但方程(1.2a)和(1.2b)被引用为 (1.2)中的第一个方程 和 (1.2)中的第二个方程。这表明,需要对文档内容有相当的语义理解才能正确解开所有引用,这超出了本次更新的范围。 - 我们目前不生成方程标签。原因包括:
- 我们不生成文本中的
\ref元素,这使得\label元素变得多余。 - 一些广泛使用的 LaTeX 渲染库不支持
\label和\ref。- Katex 不支持这一点。附加详情
- 我们不生成文本中的
- 当我们为一个块方程输出一个 array 环境时,如果这个块有多个方程编号,只有最后一个方程编号会被标记。这是因为 LaTeX 允许每个 array 只有一个方程编号。cases 环境也是如此。我们计划添加对 numcases 环境的支持,这将允许一个方程块中多个标签的存在。
February 3, 2024
- 部署新 OCR 版本 RSK-M127p2
- 修复内部错误处理
February 3, 2024
- 部署新版本:RSK-M127p1,RSK-P111p1 (
v3/pdf*) - 对表格输出进行改进。
February 2, 2024
- 部署新版本:RSK-M127,RSK-P111 (
v3/pdf*) - 初步 OCR 支持 Jordan 矩阵,改进了张量索引和手写内容。
例如,Mathpix 现在可以正确识别这样的矩阵:
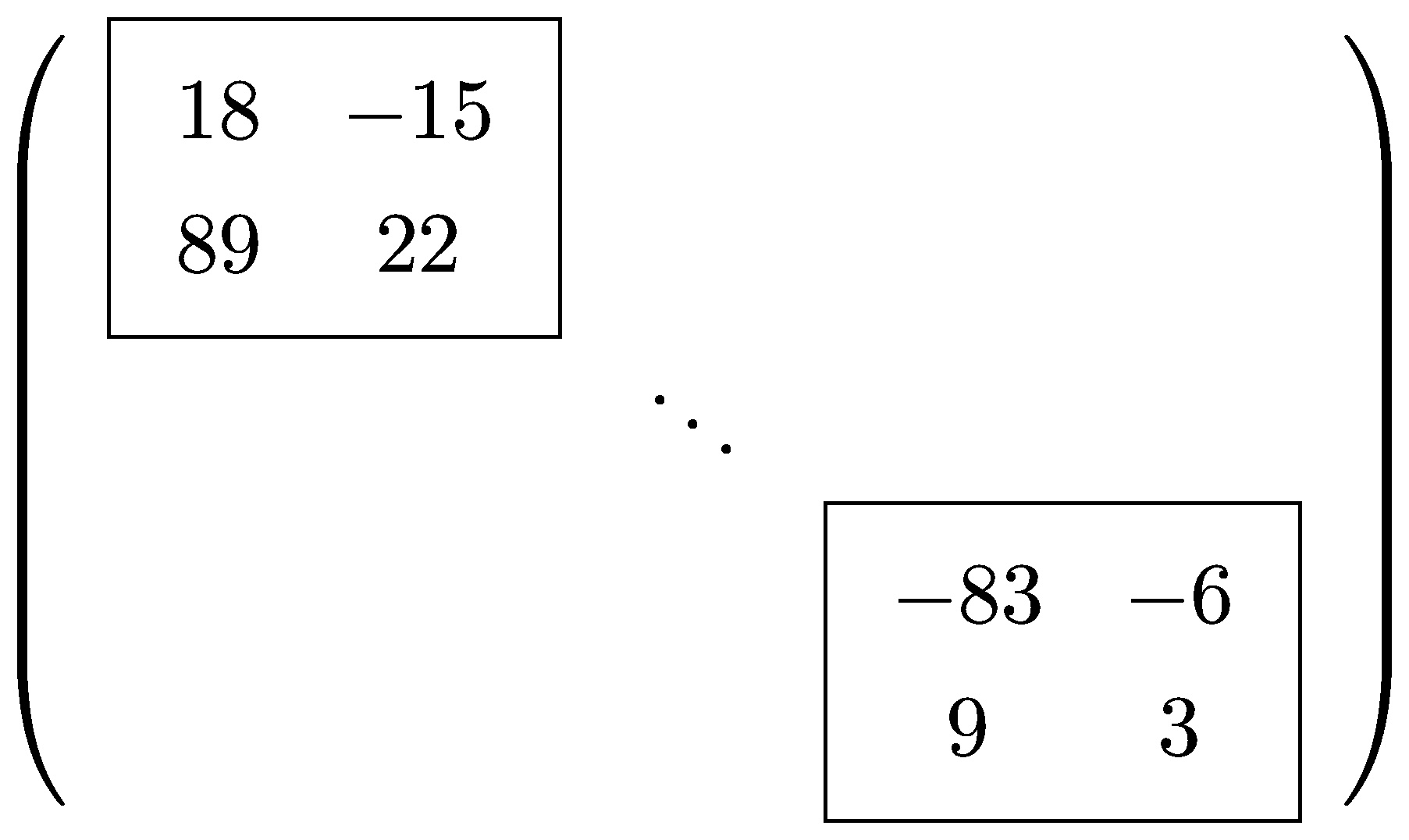
并返回结果:
\( \left(\begin{array}{ccc}\boxed{\begin{array}{cc}18 & -15 \\ 89 & 22\end{array}} & & \\ & \ddots & \\ & & \boxed{\begin{array}{cc}-83 & -6 \\ 9 & 3\end{array}}\end{array}\right) \)
January 27, 2024
- 部署新版本:RSK-M126,RSK-P110 (
v3/pdf*); - OCR 算法改进,以支持未来的化学内容发布;
January 22, 2024
- 部署新版本:RSK-M125,RSK-P109 (
v3/pdf*); - 提高了对困难图像/页面内容检测的准确性。
January 17, 2024
- 部署新版本:RSK-M124p2;
- 修改了化学输出;
January 16, 2024
- 部署新版本:RSK-M124p1;
- 将
expand_chemistry更改为include_chemistry;
January 15, 2024
- 部署新版本:RSK-M124;
- 对小图像的 OCR 改进;
January 11, 2024
- 部署新版本:RSK-M123,RSK-P108 (
v3/pdf*); - 改进了对复杂张量索引图像的 OCR 处理;
例如,对于以下图像:

结果 LaTeX 以前是:
\( \epsilon_\sigma^{\mu \nu \rho} \)
对于同一图像,新的部署现在返回:
\( \epsilon^{\mu \nu \rho}{ }_{\sigma} \)
January 27, 2024
- 部署新版本:RSK-M126,RSK-P110 (
v3/pdf*); - OCR 算法改进,以支持未来的化学内容发布;
January 22, 2024
- 部署新版本:RSK-M125,RSK-P109 (
v3/pdf*); - 提高了对困难图像/页面内容检测的准确性。
January 17, 2024
- 部署新版本:RSK-M124p2;
- 修改了化学输出;
January 16, 2024
- 部署新版本:RSK-M124p1;
- 将
expand_chemistry更改为include_chemistry;
January 15, 2024
- 部署新版本:RSK-M124;
- 对小图像的 OCR 改进;
January 11, 2024
- 部署新版本:RSK-M123,RSK-P108 (
v3/pdf*); - 改进了对复杂张量索引图像的 OCR 处理;
例如,对于以下图像:
渲染效果的差异显示了改进:

January 9, 2024
- 部署新版本:RSK-M122p1;
- 修复了当请求中使用
"include_word_data": true时的内部后处理错误;
December 28, 2023
- 部署新版本:RSK-M122,RSK-P107 (
v3/pdf*); - 线数据输出中添加了行是否为打印、手写或两者的相关信息;
图像或页面中的文本可以是打印的、手写的或两者兼有。我们通过我们的行 API 提供了这些信息。例如,对于以下图像:
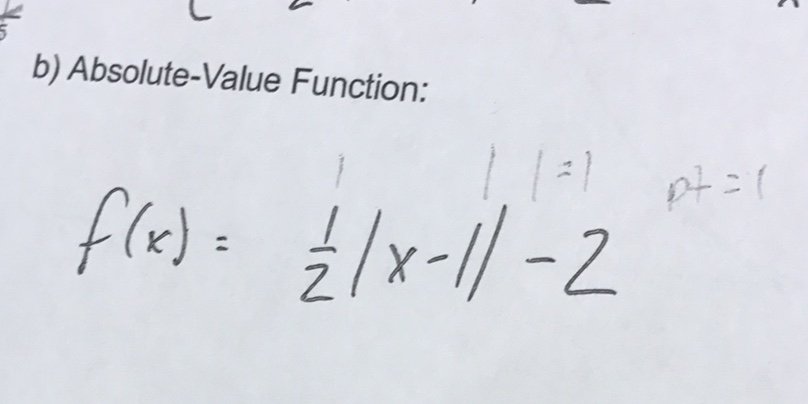
以及请求:
{
"src": "https://mathpix.com/examples/printed_handwritten_0.jpg",
"formats": [
"text"
],
"include_line_data": true
}
响应将如下所示:
{
"image_width": 808,
"image_height": 404,
"is_printed": true,
"is_handwritten": true,
"auto_rotate_confidence": 0.0,
"auto_rotate_degrees": 0,
"confidence": 1.0,
"confidence_rate": 1.0,
"text": "b) Absolute-Value Function:\n\\[\nf(x)=\\frac{1}{2}|x-1|-2\n\\]",
"languages_detected": [],
"line_data": [
{
"type": "text",
"cnt": [
[
193,
39
],
[
380,
44
],
[
419,
50
],
[
424,
55
],
[
430,
66
],
[
424,
105
],
[
419,
110
],
[
259,
110
],
[
132,
105
],
[
61,
99
],
[
39,
94
],
[
0,
77
],
[
0,
55
],
[
55,
39
]
],
"included": true,
"is_printed": true,
"is_handwritten": false,
"text": "b) Absolute-Value Function:",
"after_hyphen": false,
"confidence": 1.0,
"confidence_rate": 1.0
},
{
"type": "math",
"cnt": [
[
44,
328
],
[
44,
157
],
[
651,
157
],
[
651,
328
]
],
"included": true,
"is_printed": false,
"is_handwritten": true,
"text": "\n\\[\nf(x)=\\frac{1}{2}|x-1|-2\n\\]",
"after_hyphen": false,
"confidence": 1.0,
"confidence_rate": 1.0
}
]
}
在行数据中,句子的“is_printed”为真,而“is_handwritten”为假,而数学的“is_handwritten”为真,而“is_printed”为假。
有时,内容可以同时打印和手写。这里有一个这样的例子:
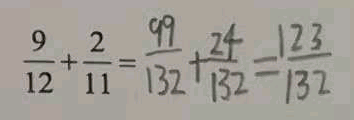
对于请求:
{
"src": "https://mathpix.com/examples/printed_handwritten_1.jpg",
"formats": [
"text"
],
"include_line_data": true
}
响应将如下所示:
{
"image_width": 354,
"image_height": 120,
"is_printed": true,
"is_handwritten": true,
"auto_rotate_confidence": 0.0,
"auto_rotate_degrees": 0,
"confidence": 0.99951171875,
"confidence_rate": 0.99951171875,
"latex_styled": "\\frac{9}{12}+\\frac{2}{11}=\\frac{99}{132}+\\frac{24}{132}=\\frac{123}{132}",
"text": "\\( \\frac{9}{12}+\\frac{2}{11}=\\frac{99}{132}+\\frac{24}{132}=\\frac{123}{132} \\)",
"languages_detected": [],
"line_data": [
{
"type": "math",
"cnt": [
[
16,
110
],
[
16,
1
],
[
338,
1
],
[
338,
110
]
],
"included": true,
"is_printed": true,
"is_handwritten": true,
"text": "\\( \\frac{9}{12}+\\frac{2}{11}=\\frac{99}{132}+\\frac{24}{132}=\\frac{123}{132} \\)",
"after_hyphen": false,
"confidence": 0.99951171875,
"confidence_rate": 0.9999904235654993
}
]
}
在
line_data 中可以看到,line 对象的 is_printed 和 is_handwritten 都设置为 true。在
v3/pdf* 端点中,lines.json 和 lines.mmd.json 输出已更新,每行都有新的 is_printed 和 is_handwritten 字段。2023 年 12 月 13 日
- 部署新版本:RSK-M121、RSK-P106(
v3/pdf*); - 增加了对 12 个新 LaTeX 命令的支持;
- 改进了对带有许多点的文本行的识别(例如目录图像中的文本行);
- 改进了对使用西里尔字母的语言的识别。
我们增加了对 12 个以前不受支持的新 LaTeX 命令的识别支持。
\xrightarrow
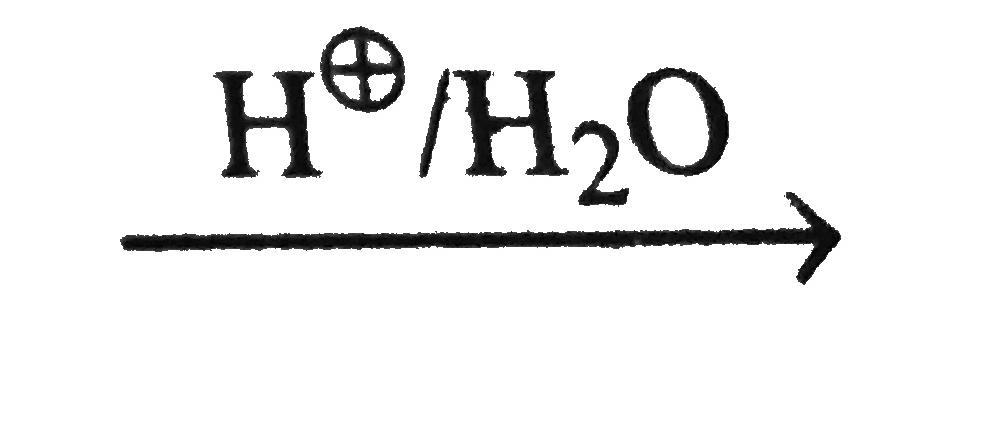
\( \xrightarrow{\mathrm{H}^{\oplus} / \mathrm{H}_{2} \mathrm{O}} \)\xlongequal
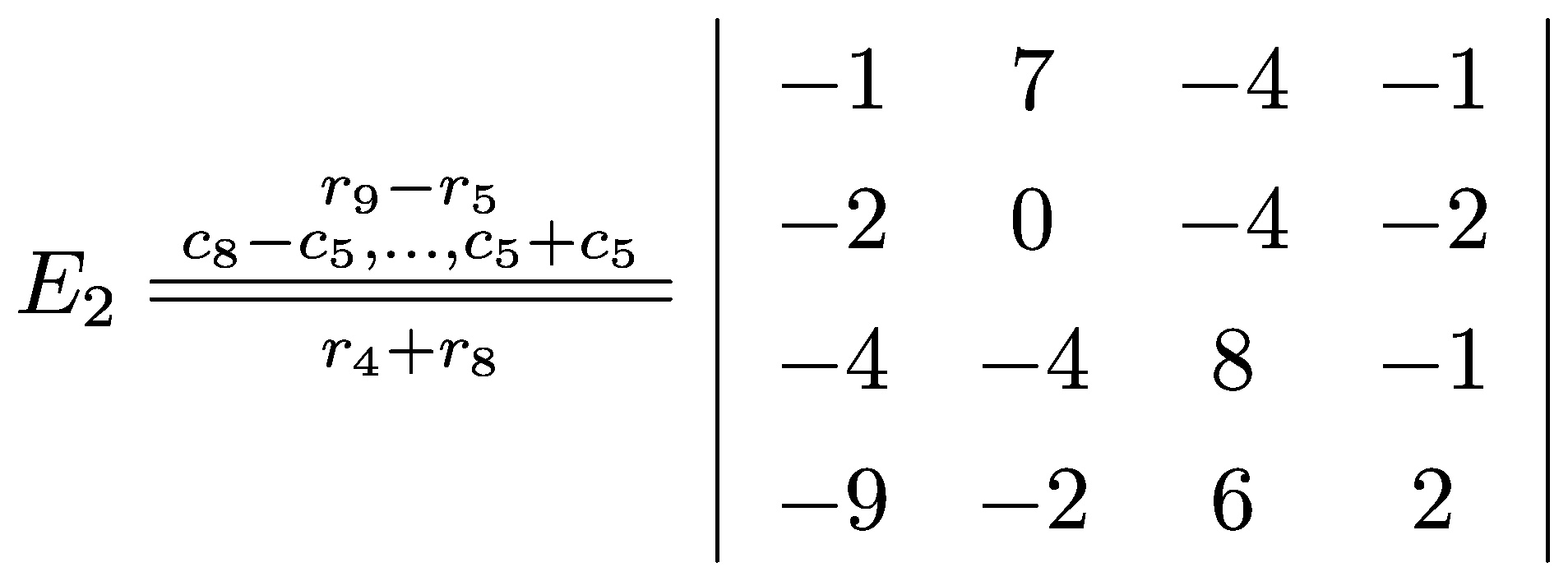
\( E_{2} \xlongequal[r_{4}+r_{8}]{\substack{r_{9}-r_{5} \\ c_{8}-c_{5}, \ldots, c_{5}+c_{5}}}\left|\begin{array}{cccc}-1 & 7 & -4 & -1 \\ -2 & 0 & -4 & -2 \\ -4 & -4 & 8 & -1 \\ -9 & -2 & 6 & 2\end{array}\right| \)\gtrdot

\( \frac{1}{g_{4}^{2}} \lessdot-\frac{2 k N_{c} \ln (v)}{g_{5}^{2}} \gtrdot 0 \)\boxtimes

\( (u \boxtimes v) \cdot(w \boxtimes x)=(v \cdot w)(u \boxtimes x) \)\downharpoonleft
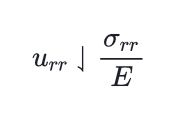
\( u_{r r} \downharpoonleft \frac{\sigma_{r r}}{E} \)\downharpoonright

\( \int \rho_{i k} d f_{i} \downharpoonright 0 \)\leftharpoondown
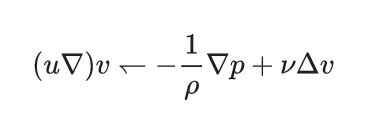
\( (u \nabla) v \leftharpoondown-\frac{1}{\rho} \nabla p+\nu \Delta v \)\leftharpoonup

\( \phi(u, v) \leftharpoonup \arctan \left[\frac{I(u, v)}{R(u, v)}\right] \)\rightharpoondown
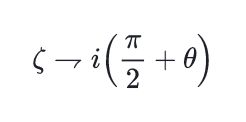
\( \zeta \rightharpoondown i\left(\frac{\pi}{2}+\theta\right) \)\rightharpoonup

\( f(t) h(t) \rightharpoonup H(\mu) \div F(\mu) \)\upharpoonleft
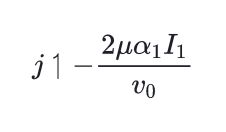
\( j \upharpoonleft-\frac{2 \mu \alpha_{1} I_{1}}{v_{0}} \)\upharpoonright
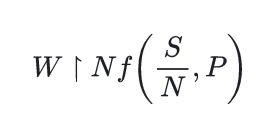
\( W \upharpoonright N f\left(\frac{S}{N}, P\right) \)2023 年 12 月 7 日
- 部署新版本(
v3/pdf),RSK-P105; - 目录页的另一项改进。
2023 年 11 月 28 日
- 部署新版本(
v3/pdf),RSK-P104; - 改进了目录页的处理。
2023 年 10 月 31 日
- 部署新版本(
RSK-M120); - 图表检测;
这是识别图表的第一步。图像支持基本图表检测。
当请求中指定
“include_line_data”:true 时,对于所有图表,我们现在在行数据响应中返回正确的 chart类型,而不是通用的diagram`。目前,检测到几种类型的图表:- 柱形图
- 条形图
- 折线图
- 饼图
- 面积图
- 散点图
图表类型可用作线对象的
"subtype": ... 字段。此列表将来会扩展其他类别。- 算法伪代码识别改进。
我们过去常常无法识别具有复杂算法伪代码的图像,例如:

对于这样的图像,返回的 MMD 现在如下所示:
Algorithm 1 Gradient Sign Dropout Layer (GradDrop Layer)
choose monotonic activation function \( f \quad \triangleright \) Usually just \( f(p)=p \)
choose input layer of activations \( A \quad \triangleright \) Usually the last shared layer
choose leak parameters \( \left\{\ell_{1}, \ldots, \ell_{n}\right\} \in[0,1] \quad \triangleright \) For pure GradDrop set all to 0
choose final loss functions \( L_{1}, \ldots, L_{n} \)
function \( \operatorname{BACKWARD}\left(A, L_{1}, \ldots, L_{n}\right) \quad \triangleright \) returns total gradient after GradDrop layer
for \( i \) in \( \{1, \ldots, n\} \) do
calculate \( G_{i}=\operatorname{sgn}(A) \circ \nabla_{A} L_{i} \quad \triangleright \operatorname{sgn}(\mathrm{A}) \) inspired by Equation 3
if \( G_{i} \) is batch separated then
\( G_{i} \leftarrow \sum_{\text {batchdim }} G_{i} \)
calculate \( \mathcal{P}=\frac{1}{2}\left(1+\frac{\sum_{i} G_{i}}{\sum_{i}\left|G_{i}\right|}\right) \quad \triangleright \mathcal{P} \) has the same shape as \( G_{1} \)
sample \( U \), a tensor with the same shape as \( \mathcal{P} \) and \( U[i, j, \ldots] \sim \operatorname{Uniform}(0,1) \)
for \( i \) in \( \{1, \ldots, n\} \) do
calculate \( \mathcal{M}_{i}=\mathcal{I}[f(\mathcal{P})>U] \circ \mathcal{I}\left[G_{i}>0\right]+\mathcal{I}[f(\mathcal{P})<U] \circ \mathcal{I}\left[G_{i}<0\right] \)
set newgrad \( =\sum_{i}\left(\ell_{i}+\left(1-\ell_{i}\right) * \mathcal{M}_{i}\right) \circ \nabla_{A} L_{i} \)
return newgrad
并且它呈现为:

虽然仍然缺少正确的缩进,但现在返回的是内容,而不是“未找到内容”错误。
2023 年 10 月 30 日
- 部署新版本 RSK-P103p6 (
v3/pdf*); - 增加了对
remove_section_numbering和preserve_section_numbering的支持。默认行为已更改为
preserve_section_numbering: True。
*请注意,
auto_number_sections、remove_section_numbering 或 preserve_section_numbering 中只有一个可以同时为 true。2023 年 10 月 27 日
- 部署新版本:RSK-M119p7、RSK-P103p5(
v3/pdf*); - 后处理改进:对于某些类别的具有挑战性的输入,我们现在返回结果而不是
内部错误。
2023 年 10 月 21 日
- 部署新版本 RSK-P103p3(
v3/pdf*); - 修复了连接不同页面的内容时出现的新行不一致问题;
- 在
\footnotetext之前生成单个新行,而不是两个新行; - 两个新行引入了一个新段落,这种行为在某些情况下会破坏渲染体验。
2023 年 10 月 19 日
- 部署新版本
RSK-M119p6; - 修复了以西里尔字母开头的列表项图像的错误段落检测问题。
2023 年 10 月 18 日
- 部署新版本
RSK-M119p5; - 此次更新的重点是更准确地将文本分成段落。
2023 年 10 月 14 日
- 部署新版本:RSK-M119p4、RSK-P103p2(
v3/pdf*); - 修复了中文符号之间的空格,该空格以前是在相邻文本行连接时生成的。
例如,对于这样的图像:

结果以前看起来像:
【甲】孔子说: “我十五岁开始有志于做学问,三十岁能独立做事情,四十岁能 (通达事理) 不被外物所迷惑,五十岁能知道哪 *extra whitespace* 些是不能为人力所支配的事情,六十岁能听得进不同的意见,到七十岁才做事能随心所欲,不会超过规矩。”此版本获得的结果不包含多余的空格,如下所示:
【甲】孔子说: “我十五岁开始有志于做学问,三十岁能独立做事情,四十岁能 (通达事理) 不被外物所迷惑,五十岁能知道哪些是不能为人力所支配的事情,六十岁能听得进不同的意见,到七十岁才做事能随心所欲,不会超过规矩。2023 年 10 月 13 日
- 部署新版本(
v3/pdf*),RSK-P103p1; - 在某些情况下改进了多项选择题答案的排序。对于 PDF 页面的这一部分:

我们过去按高度确定的顺序返回答案:
10. Demostrar que si \(a, b \in \mathbb{R}\), entonces:
a) \(|-a|=|a|\).
e) \(|a-b| \leq|a|+|b|\)
b) \(\sqrt{a^{2}}=|a|\).
f) \(||a|-| b|| \leq|a-b|\).
c) \(|a-b|=|b-a|\).
g) \(a \neq 0,\left|\frac{1}{a}\right|=\frac{1}{|a|}\).
d) \(\left|a^{2}\right|=|a|^{2}\).
h) \(b \neq 0,\left|\frac{a}{b}\right|=\frac{|a|}{|b|}\).
Now, we return the answers in the correct order:
10. Demostrar que si \(a, b \in \mathbb{R}\), entonces:
a) \(|-a|=|a|\).
b) \(\sqrt{a^{2}}=|a|\).
c) \(|a-b|=|b-a|\).
d) \(\left|a^{2}\right|=|a|^{2}\).
e) \(|a-b| \leq|a|+|b|\)
f) \(||a|-| b|| \leq|a-b|\).
g) \(a \neq 0,\left|\frac{1}{a}\right|=\frac{1}{|a|}\).
h) \(b \neq 0,\left|\frac{a}{b}\right|=\frac{|a|}{|b|}\).
2023 年 10 月 12 日
- 部署新版本
RSK-M119p3; - 提高韩语和手写中文的准确度;
- 修复了括号识别的几个问题。
这是一个示例图像:
之前的结果(缺少外括号):

当前版本的结果:

2023 年 10 月 9 日
- 部署新版本(
v3/pdf*),RSK-P103; - 更可靠地识别脚注文本;
- 初步支持目录;
- 伪代码算法现在可以搜索;
- 伪代码算法中的各行将成为
lines.json输出的一部分。
2023 年 9 月 5 日
- 部署新版本(
v3/pdf*),RSK-P101; - 增加了对页面脚注部分文本的基本支持。文本将包裹在
\footnotetext{ ... }内,而不是破坏主流,尤其是在多列文档中。
2023 年 5 月 25 日
- 部署新版本
RSK-115; - 提高了印刷和手写中文识别的质量。
2023 年 4 月 12 日
- 部署新版本
RSK-113; - 本次更新重点关注化学识别。
提醒一下,当“include_smiles”:true 是请求的一部分时,Mathpix 可以识别化学图表,例如:

并返回如下所示的 SMILES 表示:
<smiles>Cn1c(=O)c2c(ncn2C)n(C)c1=O</smiles>
改进列表:
- 支持立体化学:
- 例如,图像

转录为:
<smiles>O=S(=O)(c1ccc(F)cc1)N1C[C@@H](O)[C@H](N2CCCC2)C1</smiles>;- 支持马库什结构:
- 例如,图像

转录为
<smiles>[Z2]Nc1c(CC([R10])CSC)ncn1CC#C</smiles>;- 对超原子的基本支持:
- 未来将支持更多超原子;
- 手写和印刷化学图的识别准确率显著提高。
2023 年 2 月 22 日
- 部署新版本
RSK-111; - 增加了对新表格识别算法的支持;
- 需要进行微小的一般更改才能正确支持该算法。
v3/text 和 v3/pdf 端点中提供了一种新的表格识别算法。可以通过将 "enable_tables_fallback": true 指定为请求参数之一来启用它。我们非常关心向后兼容性。只有满足以下两个条件时,才会使用新算法:
- 我们的标准算法无法识别表格;
"enable_tables_fallback": true被指定为请求参数。
我们确保没有指定此选项的客户不会产生计算开销,因此响应时间不会受到影响。
我们投资了一种混合方法,可以解决复杂的情况,例如:
- 非常大的表格(例如具有数百个单元格的表格);
- 具有非常复杂结构的表格(例如具有许多
\multirow和\multicolumn单元格的表格); - 具有复杂内容的表格单元格的表格,例如:
- 具有复杂数学的表格单元格,如大型矩阵或多个对齐方程;
- 表格单元格包含整段文本;
- 表格中包含的文本语言比英语更难正确识别:
- 包括字母丰富的语言,如中文、日语、印地语、希伯来语、阿拉伯语等;
- 表格单元格中包含旋转文本;
- 表格单元格中包含以下图表:
- 表格单元格中包含化学图表(请注意,这些图表可以转换为 SMILES);
- 表格单元格中包含自然图像或类似图像:
- 表格仍将被识别,并在其单元格中包含图表的图像链接。
我们还将支持上述所有情况的组合。
我们现在发布的算法可能仍难以处理:
- 表格单元格中包含复杂数学,如大型矩阵或多个对齐方程;
- 表格单元格中包含图表;
- 没有文本内容的空单元格网格;
- 部分支持包含旋转文本的表格:
- 在
v3/pdf中包含旋转文本的单元格将作为图像嵌入。
我们将添加改进,以涵盖特定情况。
新算法与标准算法相比,输出结果存在一些差异:
- 列对齐始终居中;
- 所有单元格都有所有边框(顶部、底部、右侧和左侧)。
2023 年 2 月 1 日
- 部署新版本
RSK-110; - 增加了对新 LaTeX 命令的支持:
\measuredangle、\grave、\bumpeq和\amalg; - 改进了用
\lceil、\rceil、\lfloor和\rfloor与\left和\right组合表达的构造的识别; - 改进了文本模式下方程的格式(详情见下文);
- 改进了对下标中包含大子方程的方程的识别;
- 改进了对手写法语的识别;
- 改进了对手写德语的识别;
- 改进了对手写中文的识别;
- 改进了对手写日语的识别;
- 总体改进(新的数据迭代)。
默认的“文本”输出已更改,例如,请参见以下公式:

来自当前“文本”输出:
\( y=mx+b \)\n\( x=y^{2}-1 \)
and two asciimath equation outputs, to:
\( \begin{array}{l} y = mx + b \\ x=y^{2}-1 \end{array} \)
with one single asciimath equation output:
{:[y=mx+b],[x=y^(2)-1]:}
这将使“文本”派生格式与当前带有左括号的方程式返回的格式更加一致:

当前产生此“文本”输出:
\( \left\{\begin{array}{l}2 x+8 y=21 \\ 6 x-4 y=14\end{array}\right. \)
以及这个“asciimath”输出:
{[2x+8y=21],[6x-4y=14]:}
由于我们已经在某些情况下发出了(例如,没有括号的方程式在“=”符号周围对齐,而不是左对齐),
v3/text 的 asciimath 如下所示:{:[2x+8y=21],[6x-4y=14]:}
我们认为此更新是针对不一致的错误修复,而不是可能破坏向后兼容性的新功能。
通常,我们的 API 希望输入的微小变化会导致输出的微小变化。例如,从公式 2 中删除左括号只会将
v3/text asciimath 从:{[2x+8y=21],[6x-4y=14]:}
到:
{:[2x+8y=21],[6x-4y=14]:}
这比之前的行为变化要小,之前的行为是减去左括号会得到两个方程式而不是一个。
2023 年 1 月 30 日
- 部署新版本
RSK-109; - 改进了对孤立符号的识别。
2023 年 1 月 12 日
- 部署新版本
RSK-108; - 改进了对包含混合数学和俄语文本的图像的处理。
2022 年 12 月 2 日
- 部署新版本
RSK-107p2; - 数组间距、对齐数组和类似数组的变化,
&和\\现在总是有空格(即使请求中有rm_spaces); - 视觉上不美观的方程式块被转换为左对齐,而不是保持错误的对齐。
2022 年 11 月 25 日
- 部署新版本
RSK-107; - 与工作表裁剪、内容附近带有强边框或虚线边框的小图像相关的改进。
2022 年 11 月 22 日
- 部署新版本
RSK-106; - 与 PDF 页面中参考文献格式相关的改进,尤其是带有绿色/红色链接框的页面。
2022 年 11 月 15 日
- 部署新版本
RSK-105; - 对处理缩小和放大图像的一般改进。输出格式或错误特征没有变化。
2022 年 11 月 14 日
- 部署新版本
RSK-104p1; - 在某些情况下,块数学的格式已修复,其中方程式在文本模式下被错误保存。
2022 年 11 月 11 日
- 部署新版本
RSK-104; - 图像解析模块的逐步改进。包括对包含多行文本的图像的修复。手写数据的准确性提高。输出格式没有变化。
2022 年 11 月 3 日
- 部署新版本
RSK-103p1; - 修复了字符串后处理问题。
在此版本中,我们更改了以下字符的默认 Markdown/LaTeX:
# -> \#
虽然
# 在 Markdown 中工作正常,并且与 \# 的行为相同,但前者在 LaTeX 编译时会出现问题,而 \# 在 LaTeX 中可以顺利通过。我们选择始终使用 LaTeX 的 \# 而不是 #,以确保输出的兼容性更高,减少出现问题的可能性。更新后的字符 \# 兼容 Markdown 和 LaTeX。未经转义的
# 将不再出现在 OCR Markdown / LaTeX 输出中。替代的数学格式,如 Asciimath,不受此更改的影响,此更改仅涉及 Markdown / LaTeX。
2022年10月21日
2022年6月6日
- 解决了影响两列 PDF 处理的关键错误;
- 现在您可以请求仅处理 PDF 中的某些页面子集,通过 新的 page_ranges 字段;
- 推出了延迟改进,使所有端点受益,将处理时间平均减少了 30%;
- 现在可以通过 以下端点 查询每小时的 API 使用情况。
2022年4月27日
- 更新了 PDF 行数据的表示方式,从使用矩形区域改为多边形轮廓(这对手写 PDF 特别有帮助,因为文本行通常不是矩形的);
- 向逐行数据结构中添加了页面尺寸;
- 逐行数据有两个可用的数据结构:
- 原始 PDF 行数据:这是搜索的理想数据结构;不包含标题、摘要等的上下文注释;
- 上下文增强的 PDF mmd 行数据:您可以使用此数据结构重新创建完整的文档,包括标题、摘要等的上下文注释(请参见此处的语法);
- 发布了一个 Github 仓库,包含了客户端代码,用于使用 Mathpix 数字墨水 API 进行实时绘图,包含了利用用户操作(如涂鸦和删除内容)完全工作的示例。
2022年4月18日
- 添加了 EU 服务器区域(AWS 区域 eu-central-1),以减少欧洲客户的延迟,同时遵守 GDPR:
- 使用我们的 EU 专用 URL https://eu-central-1.api.mathpix.com/ 确保在欧洲进行处理;
- 现在可以在客户端应用代码中使用应用令牌进行身份验证;
- 新的应用令牌路由提供了一个
include_strokes_session_id标志,当设置为true时,返回一个strokes_session_id字符串,可用于v3/strokes调用中,实现带有实时更新的数字墨水会话:- 使用
session_id的笔迹端点定价可以在 这里 查找;
- 使用
- 添加了对基本手写 PDF 的 OCR 支持。
2022年3月28日
- 现在可以通过新的
GET v3/pdf/<pdf_id>.lines.json端点获取 PDF 的详细逐行数据,包括几何坐标; - 改进了
v3/text端点的鲁棒性:- 我们正确解读包含数学和文本的复杂布局的能力得到改善,边缘情况处理和处理倾斜图像以及其他常见的图像失真情况得到了显著提升。
2022年3月14日
- 我们的新 OCR 模型具有严格的语法正确性保证,解决了偶尔出现的 LaTeX 字符串格式错误问题,之前这些错误可能导致渲染错误,如双下标、双上标、格式错误的表格以及其他语法问题。这个问题已经从根本上得到解决。语法问题基本完全修复;
- 废弃了
\atop命令,推荐使用\substack。
2022年2月8日
我们最近切换到一个更快的数据库来保存图像和 PDF 数据。下周,我们将停用旧数据库。这将导致 2021年12月1日之前的 OCR API 图像结果日志数据无法通过
GET v3/ocr-results 端点访问。请注意,我们已经将所有 PDF 数据迁移到新数据库,因此 PDF 数据不会丢失。2021年11月15日
- 部署了对 OCR 引擎的增量更新,导致:
- 手写识别显著改进,包括根据上下文区分符号;
- 表格解析准确性改进;
- 明显减少错误。
2021年9月2日
- 部署了图像解析模块的核心算法更新,显著提高了所有端点的准确性和边缘情况处理能力;
- 更新的 CLI 增加了额外的转换类型;
- 化学图表 OCR 取得显著进展;
- 支持异步图像处理。
2021年7月27日
- 增加对泰米尔语、泰卢固语、古吉拉特语和孟加拉语的支持;
- 更新了 OCR 以使用更有效的中文字符表示方式,提高了准确性和覆盖范围;
- 增加对
\bigcirc的支持。
2021年7月19日
- 支持发送图像二进制数据以降低图像上传延迟;
- 支持标签,允许您将属性与请求关联,并通过使用标签在 /v3/ocr-results 查询 中检索相关请求;
- PDF 处理更新:
- 修复了跳过页面的错误;
- 改进了对外语 PDF 的处理;
- 增加对 可配置数学分隔符 的支持。
2021年4月12日
- 新加坡服务器提供更快的亚洲客户 API 延迟;
- 三角形图表 OCR 现在支持常见于三角函数教材的图表;
- 为化学图表 OCR 添加了 InChI 选项。
2021年4月2日
- 向
v3/text端点添加了 include_word_data 参数,设置为true时,返回逐字信息,包括每个单词的单独结果、置信度值和轮廓坐标; - 打印化学图表 OCR 的测试版返回 SMILES 格式(请求参数)。
2021年3月10日
- 新的 v3/pdf API 端点(测试版);
- PDF 转换 CLI 工具;
- 修复了
v3/text处理杂乱图像的各种错误; - 对所有端点的手写识别和打印表格识别进行了增量改进;
- 增加对以下打印字符的支持:
\nvdash
\nvDash
\bigvee
\bigwedge
\fallingdotseq
\risingdotseq
\mho
\unlhd
\unrhd
\overleftrightarrow
\bigodot
2021 年 2 月 7 日
- 支持 三角形几何图检测。
2021 年 1 月 5 日
- 改进了数学手写识别;
- 改进了印刷的罗马尼亚语、波兰语、塞尔维亚语、乌克兰语识别;
- 增加了对以下 LaTeX 字符的支持:
\varsigma
\llcorner
\lrcorner
\uplus
\biguplus
\triangleright
\triangleleft
\dddot
\circledast
\rtimes
\ltimes
\supseteqq
\oiiint
\supsetneqq
\rightsquigarrow
\Vdash
\models
2020年12月1日
- 为
v3/latex和v3/batch添加了自动旋转功能(请参见 请求参数 和 结果对象); - 对
v3/latex和v3/batch的文本/数学定位性能进行了显著的准确性改进,无论是ocr=["math"](默认)还是ocr=["math", "text"],这都导致了错误率降低和不良结果减少。
2020年11月12日
- 为
v3/text添加了自动旋转功能。
像这样的图像现在在
v3/text 中也能正常工作: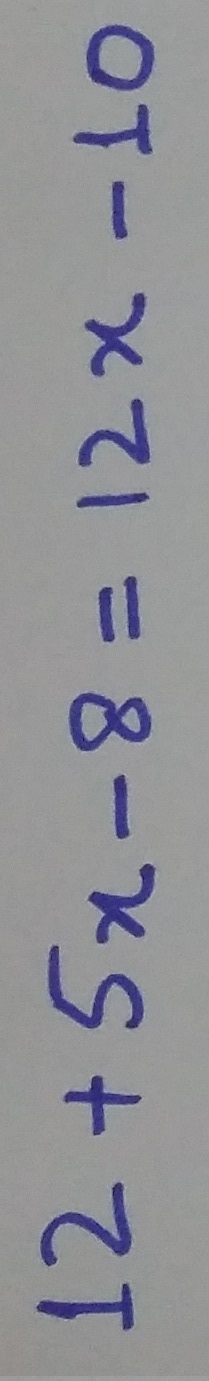
自动旋转的目标是在任何处理之前选择接收图像的正确方向。自动旋转的结果如下:

我们很快会将这些功能添加到
v3/latex 和 v3/batch 中。我们实施了一个非常保守的旋转置信度阈值,这意味着如果可能的话,您仍然应该尝试用正确方向的图像调用 API!有关自动旋转的 API 文档:
2020年11月9日
v3/text的一般改进;
首先,我们在更大的数据集上训练了我们的模型,导致整体准确性提高。
其次,我们提高了预测的精度,但在某些情况下可能会稍微降低预测的召回率。以下是一个示例图像,以前我们的
v3/text 尝试读取底部,裁剪了图像的部分内容:
现在,
v3/text 会忽略这些部分,输出比以前更干净。该端点仍然会尝试读取图像中的所有内容(与 v3/latex 端点不同,后者尝试读取主要方程),但在读取不寻常的图像部分时会稍微减少侵略性,以避免产生无用的输出。- 化学图表检测;
我们在 LineData 对象中添加了一个新字段
subtype,以便可以向 API 客户端返回更多关于图表的信息。目前 subtype 只能是 chemistry,但更多的图表子类型即将推出。请参见带有化学图表的示例请求:化学图表示例。
- 增加了在 accounts.mathpix.com OCR 仪表板上创建和禁用新 API 密钥的功能;
- 增加了邀请用户(以便访问 API 密钥、使用统计信息、图像结果仪表板)到 accounts.mathpix.com OCR 仪表板的功能。
2020年10月14日
- 增加了对以下字符的支持:
«
»
\gtrless
\lessgtr
\nsucceq
\npreceq
\llbracket
\rrbracket
\curvearrowright
\curvearrowleft
№
- 提高了以下方面的准确性:
- 手写体(数学和文本);
- 印刷的印地语语言识别;
- 表格和矩阵;
- 现在我们支持带有 alpha 通道的无背景 PNG。
2020年8月14日
- 添加了
include_line_data参数,文档请参见 https://docs.mathpix.com/#linedata-object; - 示例可以在 https://mathpix.com/docs/ocr/examples#line-data 找到。
2020年8月1日
2020年7月13日
- 将
\dots替换为\ldot或\cdot; - 在适当的时候预测空的花括号,如化学图像中的
{}; - 修复了
v3/text的一个错误,该错误导致非常宽的文本行被跳过; - 提高了手写数学的准确性;
- 提高了表格预测的准确性;
- 提高了印刷的印地语和中文文本的照片图像的准确性;
- 添加了对集合符号中
\mid预测的支持; - 添加了对以下语言的支持:捷克语、土耳其语、丹麦语。
2020年7月9日
- 添加了新的端点以检索 OCR 结果: https://docs.mathpix.com/#get-ocr-results-v3-ocr-results。
2020年7月1日
- 跳过
v3/text中导致无用结果的图表。
这是选择
v3/text 而非 v3/latex 的又一个理由!v3/text 智能地跳过图表!