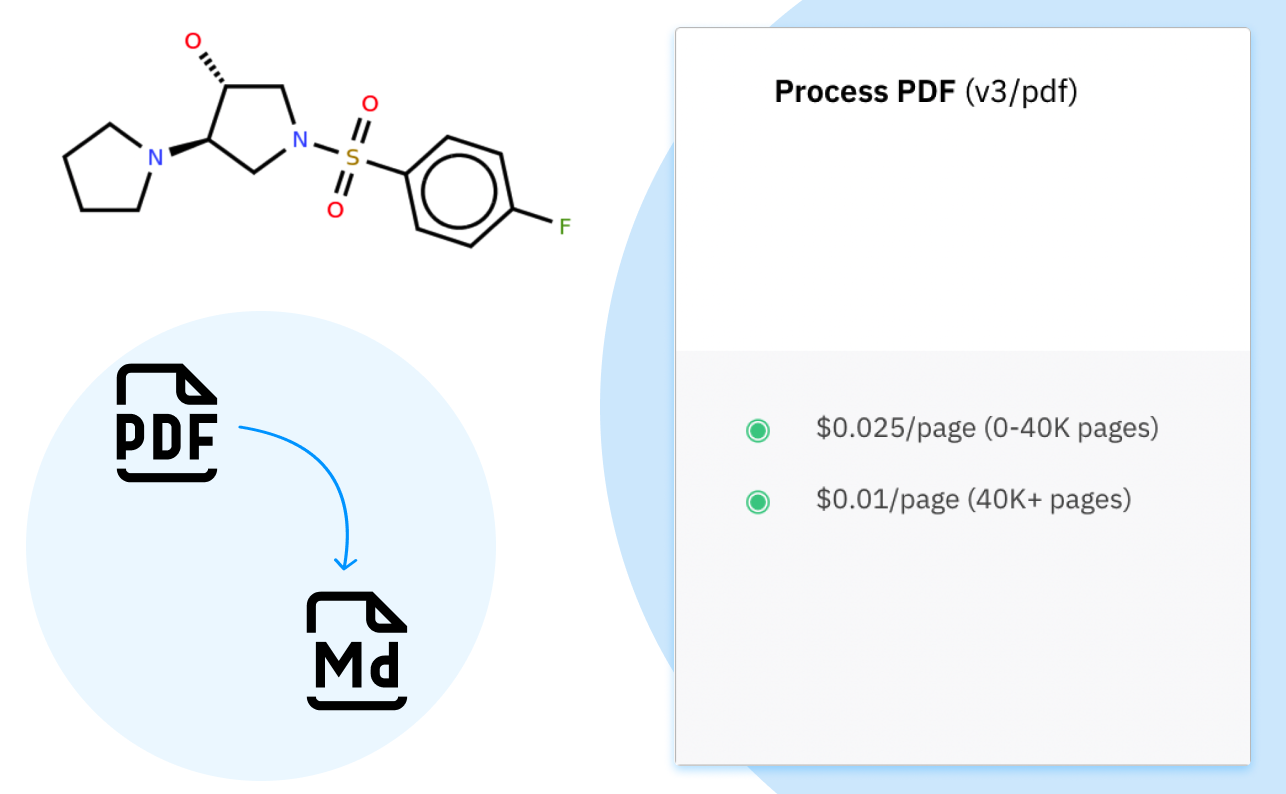
PDF API 价格降低
我们正在降低 PDF API 的价格,为我们的客户提供处理大量 PDF 文档的更实惠的选择。价格调整立即生效:从 6 月 1 日起,PDF API 客户将按新的折扣价格计算 5 月的 PDF 使用费用。
旧价格:
$0.1/页(0-1K 页)
$0.05/页(1K+ 页)
$0.05/页(1K+ 页)
新价格:
$0.025/页(0-40K 页)
$0.01/页(40K+ 页)
$0.01/页(40K+ 页)
如果您有非常大的 PDF 集合(超过一百万页),希望进行数字化处理,请联系 sales@mathpix.com,以便我们可以给您提供以折扣价购买 PDF 页码积分的报价。
适用于 LLM 的 PDF 纯 Markdown 输出
我们广泛使用 Mathpix Markdown,因为它是一种表达力强且功能丰富的标记语言,适用于处理 STEM 文档,解决了普通 Markdown 的许多限制。然而,现代 LLM 通常以普通 Markdown 进行训练,对 Mathpix Markdown 的了解较少,因此我们现在在 API 中支持纯
.md 输出,除了 Mathpix Markdown 输出 .mmd 外:例如,表格在我们的纯 Markdown 输出中使用标准 Markdown 语法表示,例如:
| Syntax | Description |
| ----------- | ----------- |
| Header | Title |
| Paragraph | Text |
而不是使用 Mathpix Markdown 语法
\begin{tabular} … \end{tabular}(这是与 LaTeX 相同的语法)。纯 Markdown 输出中的章节标题使用更标准的
# 章节 和 ## 小节。请注意,Markdown 输出还默认使用美元符号分隔符
$...$ 和 $$ … $$ 来表示数学表达式,而不是我们默认的 Mathpix Markdown 输出中的 \( … \) 和 \[ … \] 分隔符。我们发现这大大提高了与 ChatGPT 的兼容性。更快的 PDF 处理速度
我们已经将每页的平均处理时间缩短了超过 50%。我们将在不久的将来继续优化 PDF 处理延迟。
v3/text 端点对多列图像的基本支持
我们刚刚在图像处理端点(v3/text)中引入了对多列图像的基本支持(我们之前已经在 v3/pdfs 中支持了这一点)。我们将在不久的将来继续改善图像处理端点和 PDF 处理端点的布局分析能力。
改进的化学结构图识别
图像到 SMILES 的转换整体上已显著改进,现在包括了对立体化学和 Markush 结构的支持。
立体化学:
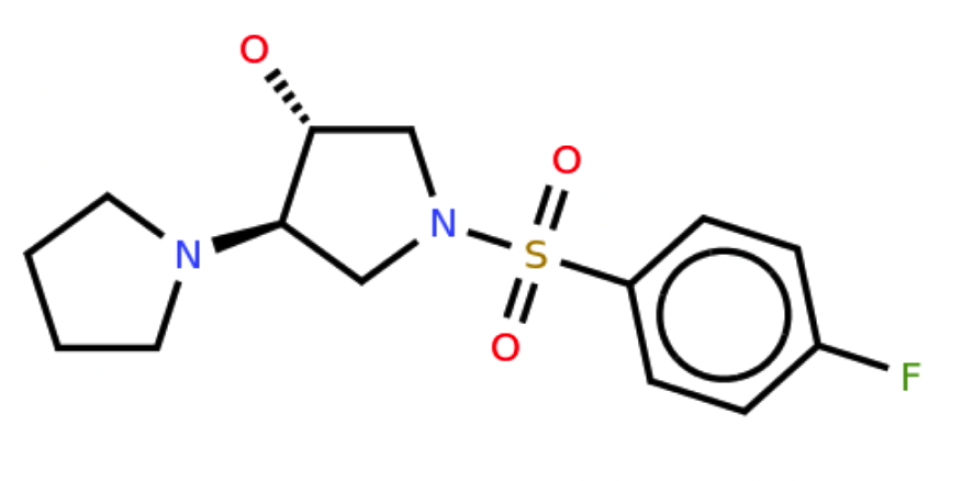
生成的 SMILES:
O=S(=O)(c1ccc(F)cc1)N1C[C@@H](O)[C@H](N2CCCC2)C1Markush 结构:
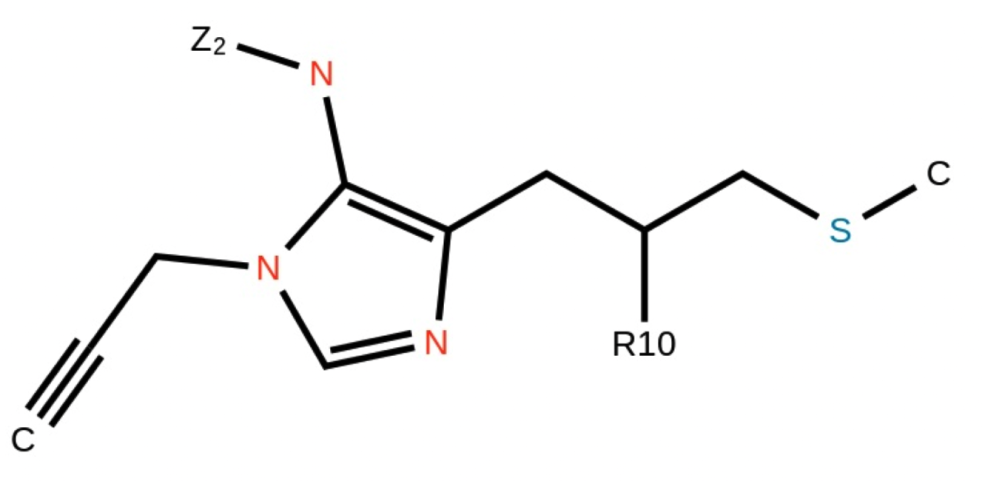
生成的 SMILES:
[Z2]Nc1c(CC([R10])CSC)ncn1CC#C